Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right product.
Agenta is an open-source LLMOps platform that streamlines collaboration for building and managing reliable LLM.
Last updated: March 1, 2026
OpenMark AI benchmarks over 100 LLMs on your specific tasks, delivering rapid insights into cost, speed, quality, and stability without setup.
Last updated: March 26, 2026
Visual Comparison
Agenta
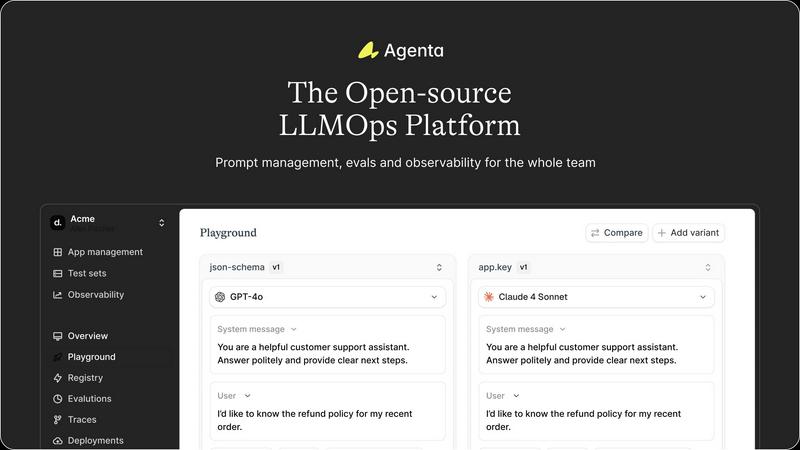
OpenMark AI

Feature Comparison
Agenta
Centralized Prompt Management
Agenta provides a unified platform for storing and managing prompts, evaluations, and traces. This centralization allows teams to easily access and collaborate on prompts without the confusion of disparate tools, ensuring a more organized workflow.
Automated Evaluation Processes
With Agenta, teams can implement automated evaluation processes that replace guesswork with systematic experimentation. Users can create experiments, track results, and validate changes, allowing for evidence-based decision-making in LLM development.
Comprehensive Observability
Agenta offers robust observability features that allow teams to trace requests and pinpoint failure points in production systems. This functionality is critical for debugging and helps maintain high performance by providing insights into how models behave in real-world scenarios.
Collaborative Development Environment
Agenta fosters collaboration among product managers, developers, and domain experts. Its intuitive UI enables non-technical team members to participate in prompt editing and evaluation processes, bridging the gap between technical and non-technical stakeholders.
OpenMark AI
User-Friendly Task Configuration
OpenMark AI features an intuitive task configuration interface that allows users to describe their benchmarking tasks in simple language. This accessibility ensures that even those without extensive technical knowledge can effectively set up their tests and receive meaningful results.
Comprehensive Model Comparison
The platform supports benchmarking against over 100 different AI models, enabling users to gain a comprehensive understanding of which models perform best for their specific tasks. This wide-ranging comparison helps teams make informed decisions based on real-world performance metrics.
Real-Time API Results
OpenMark AI provides side-by-side results of real API calls, ensuring that users receive accurate data reflective of actual performance. This real-time feedback is crucial for developers looking to understand how different models behave under similar conditions.
Cost Efficiency Analysis
One of the standout features of OpenMark AI is its ability to analyze the cost efficiency of different models. Users can see not only the quality of outputs but also how the costs compare against each model, enabling them to make financially sound decisions when selecting an AI solution.
Use Cases
Agenta
Rapid Prototype Development
Agenta can significantly accelerate the development of prototypes for LLM applications. By providing a structured environment for prompt experimentation and evaluation, teams can quickly iterate and refine their models based on real-time feedback.
Cross-Functional Team Collaboration
With Agenta, cross-functional teams can collaborate more effectively. Product managers, developers, and domain experts can work together in a single workflow, enhancing communication and reducing the chances of misalignment throughout the development process.
Systematic Error Debugging
When issues arise in production, Agenta's observability tools allow teams to trace requests and identify the root causes of errors. This capability transforms debugging from guesswork into a systematic process, improving the reliability of LLM applications.
Evidence-Based Model Evaluation
Agenta enables teams to replace subjective assessments with evidence-based evaluations of model performance. By integrating feedback from domain experts and running systematic experiments, teams can make informed decisions about model adjustments and improvements.
OpenMark AI
Model Selection for AI Features
Developers can utilize OpenMark AI to select the most appropriate model for their AI-driven features by benchmarking performance on specific tasks. This ensures that the chosen model aligns with both performance goals and budget constraints.
Pre-Deployment Validation
Product teams can validate their model choices before deployment by testing outputs for consistency and quality. This capability reduces the risk associated with deploying a less effective model, ensuring a smoother transition from development to production.
Cost-Benefit Analysis
Businesses seeking to optimize their AI spending can leverage OpenMark AI to perform a detailed cost-benefit analysis. By comparing the actual costs of API calls with the outputs generated, organizations can identify the best value options.
Research and Development
Researchers can use OpenMark AI to experiment with various models for academic or product development purposes. The tool allows for thorough testing of hypotheses regarding model performance across different tasks and environments.
Overview
About Agenta
Agenta is an open-source LLMOps platform designed to empower AI development teams by providing the necessary infrastructure to build, evaluate, and deploy reliable Large Language Model (LLM) applications. The platform directly addresses critical challenges in modern AI development, such as the unpredictability of LLMs and the lack of structured, collaborative processes. These challenges often result in disorganized workflows, with prompts scattered across various tools like Slack, Google Sheets, and emails, leading to siloed teams and unvalidated deployments. Agenta acts as a centralized hub for developers, product managers, and subject matter experts, facilitating prompt experimentation, systematic evaluations, and production debugging using real data. Its primary value proposition is transforming chaotic workflows into evidence-based, repeatable LLMOps best practices. By integrating prompt management, automated evaluation, and comprehensive observability, Agenta enables teams to iterate rapidly, validate changes effectively, and maintain visibility into system performance, significantly reducing risks and time-to-production for LLM-driven features.
About OpenMark AI
OpenMark AI is an innovative web application designed specifically for task-level benchmarking of large language models (LLMs). It allows users to articulate their testing requirements in plain language, facilitating the benchmarking of over 100 AI models within a single session. By running identical prompts across multiple models, users can effectively compare key metrics such as cost per request, latency, scored quality, and stability, providing insights into the variance of model outputs rather than relying on potentially misleading singular results. This is particularly valuable for developers and product teams who need to evaluate or validate AI models before deploying features that incorporate artificial intelligence.
OpenMark AI eliminates the complexity of managing multiple API keys by using a credit system for hosted benchmarking, making it easier to conduct comprehensive comparisons without the need for extensive configuration. Users benefit from real-time results based on actual API calls rather than pre-cached marketing data, making the tool essential for those who prioritize cost efficiency and consistent performance over simply choosing the lowest-priced token option. The platform supports a wide array of models and is designed to assist teams in pre-deployment decisions, ensuring they select the most suitable model for their specific workflow while maintaining budget considerations. OpenMark AI offers both free and paid plans, providing flexibility according to user needs.
Frequently Asked Questions
Agenta FAQ
What is LLMOps?
LLMOps, or Large Language Model Operations, refers to the practices and frameworks involved in managing the lifecycle of LLM applications, including their development, evaluation, deployment, and monitoring.
How does Agenta improve collaboration among teams?
Agenta improves collaboration by providing a centralized platform where product managers, developers, and domain experts can work together. This eliminates silos and allows for transparent communication and shared access to prompts and evaluations.
Can Agenta integrate with existing tools and frameworks?
Yes, Agenta is designed to integrate seamlessly with various frameworks and tools, including LangChain and OpenAI. This flexibility allows teams to leverage their existing tech stack without vendor lock-in.
Is Agenta suitable for teams new to LLM development?
Absolutely. Agenta is designed to support teams at all levels of LLM maturity. Its structured processes and user-friendly interface make it an excellent choice for both newcomers and experienced teams looking to optimize their workflows.
OpenMark AI FAQ
What types of models can I benchmark with OpenMark AI?
OpenMark AI supports a wide variety of models from leading AI providers, including OpenAI, Anthropic, and Google, enabling users to benchmark over 100 different LLMs.
Do I need to manage multiple API keys to use OpenMark AI?
No, OpenMark AI streamlines the process by utilizing a credit system for hosted benchmarking, which means you do not need to configure separate API keys for each model comparison.
Is OpenMark AI suitable for non-technical users?
Yes, the user-friendly interface allows individuals without extensive technical knowledge to easily describe tasks and benchmark models, making it accessible to a broader audience.
What kind of results can I expect from OpenMark AI?
Users can expect detailed results that include cost per request, latency, scored quality, and stability metrics, allowing for a comprehensive evaluation of model performance based on real API calls.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed specifically for AI development teams to build, evaluate, and manage reliable large language model applications. It serves as a centralized hub that addresses common challenges in modern AI workflows, such as the unpredictability of LLMs and fragmented collaboration among teams. Users often seek alternatives to Agenta for various reasons, including pricing considerations, specific feature requirements, or compatibility with different technical environments. When choosing an alternative, it's important to assess the platform's capabilities in prompt management, evaluation automation, and observability to ensure it meets your team's unique needs and enhances productivity.
OpenMark AI Alternatives
OpenMark AI is a powerful web application designed for benchmarking over 100 large language models (LLMs) on various tasks, focusing on key metrics such as cost, speed, quality, and stability. This tool is particularly beneficial for developers and product teams seeking to make informed decisions about AI model selection before deploying features. Users often search for alternatives to OpenMark AI due to factors like pricing, specific feature sets, or platform compatibility that may better suit their unique project needs. When considering alternatives, it is essential to evaluate the specific functionalities offered, such as user interface design, supported models, and benchmarking capabilities. Additionally, users should assess the pricing structure, including free and paid plans, and the degree of support provided for integration and usage. Ultimately, finding the right tool hinges on identifying a solution that aligns with both project requirements and budget constraints.