Agenta
Agenta is an open-source LLMOps platform that streamlines collaboration for building and managing reliable LLM.
Visit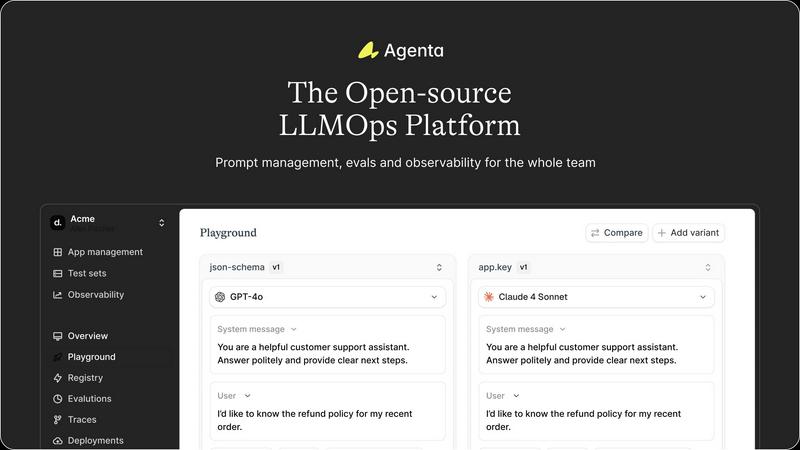
About Agenta
Agenta is an open-source LLMOps platform designed to empower AI development teams by providing the necessary infrastructure to build, evaluate, and deploy reliable Large Language Model (LLM) applications. The platform directly addresses critical challenges in modern AI development, such as the unpredictability of LLMs and the lack of structured, collaborative processes. These challenges often result in disorganized workflows, with prompts scattered across various tools like Slack, Google Sheets, and emails, leading to siloed teams and unvalidated deployments. Agenta acts as a centralized hub for developers, product managers, and subject matter experts, facilitating prompt experimentation, systematic evaluations, and production debugging using real data. Its primary value proposition is transforming chaotic workflows into evidence-based, repeatable LLMOps best practices. By integrating prompt management, automated evaluation, and comprehensive observability, Agenta enables teams to iterate rapidly, validate changes effectively, and maintain visibility into system performance, significantly reducing risks and time-to-production for LLM-driven features.
Features of Agenta
Centralized Prompt Management
Agenta provides a unified platform for storing and managing prompts, evaluations, and traces. This centralization allows teams to easily access and collaborate on prompts without the confusion of disparate tools, ensuring a more organized workflow.
Automated Evaluation Processes
With Agenta, teams can implement automated evaluation processes that replace guesswork with systematic experimentation. Users can create experiments, track results, and validate changes, allowing for evidence-based decision-making in LLM development.
Comprehensive Observability
Agenta offers robust observability features that allow teams to trace requests and pinpoint failure points in production systems. This functionality is critical for debugging and helps maintain high performance by providing insights into how models behave in real-world scenarios.
Collaborative Development Environment
Agenta fosters collaboration among product managers, developers, and domain experts. Its intuitive UI enables non-technical team members to participate in prompt editing and evaluation processes, bridging the gap between technical and non-technical stakeholders.
Use Cases of Agenta
Rapid Prototype Development
Agenta can significantly accelerate the development of prototypes for LLM applications. By providing a structured environment for prompt experimentation and evaluation, teams can quickly iterate and refine their models based on real-time feedback.
Cross-Functional Team Collaboration
With Agenta, cross-functional teams can collaborate more effectively. Product managers, developers, and domain experts can work together in a single workflow, enhancing communication and reducing the chances of misalignment throughout the development process.
Systematic Error Debugging
When issues arise in production, Agenta's observability tools allow teams to trace requests and identify the root causes of errors. This capability transforms debugging from guesswork into a systematic process, improving the reliability of LLM applications.
Evidence-Based Model Evaluation
Agenta enables teams to replace subjective assessments with evidence-based evaluations of model performance. By integrating feedback from domain experts and running systematic experiments, teams can make informed decisions about model adjustments and improvements.
Frequently Asked Questions
What is LLMOps?
LLMOps, or Large Language Model Operations, refers to the practices and frameworks involved in managing the lifecycle of LLM applications, including their development, evaluation, deployment, and monitoring.
How does Agenta improve collaboration among teams?
Agenta improves collaboration by providing a centralized platform where product managers, developers, and domain experts can work together. This eliminates silos and allows for transparent communication and shared access to prompts and evaluations.
Can Agenta integrate with existing tools and frameworks?
Yes, Agenta is designed to integrate seamlessly with various frameworks and tools, including LangChain and OpenAI. This flexibility allows teams to leverage their existing tech stack without vendor lock-in.
Is Agenta suitable for teams new to LLM development?
Absolutely. Agenta is designed to support teams at all levels of LLM maturity. Its structured processes and user-friendly interface make it an excellent choice for both newcomers and experienced teams looking to optimize their workflows.
Explore more in this category:
Similar to Agenta
MCPize is a marketplace where developers can discover, install, and manage 1,000+ premium MCP servers while publishers keep 80% of revenue.
JustHunt is the premier launchpad for startups, offering guaranteed visibility and community feedback to enhance your product's success.
act101 is a native Rust binary MCP server providing 163 grammars and 183 AST operations for AI agents to securely refactor and port code on your.
Headless Domains provides AI agents with portable, verifiable web identities for trusted authentication across apps, APIs, and marketplaces.
LoadTester enables engineering teams to run distributed HTTP and API load tests from browser or CI/CD with live analytics and zero infrastructure.
ProcessSpy is an advanced, native macOS process monitor offering real-time analytics, JavaScript filtering, and detailed system insights for power.