Fallom vs OpenMark AI
Side-by-side comparison to help you choose the right product.
Fallom delivers AI-native observability for LLMs, enabling real-time tracking and cost analysis for optimal performance.
Last updated: February 28, 2026
OpenMark AI benchmarks 100+ LLMs on your task: cost, speed, quality & stability. Browser-based; no provider API keys for hosted runs.
Visual Comparison
Fallom
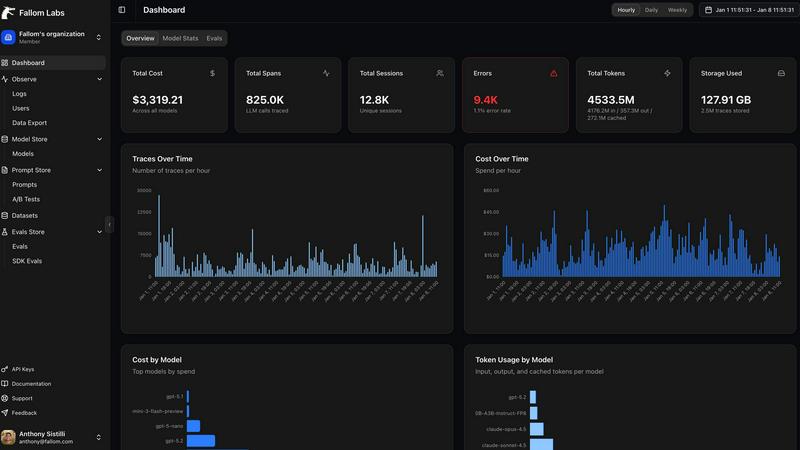
OpenMark AI

Overview
About Fallom
Fallom is an innovative AI-native observability platform designed specifically for the unique demands of monitoring and optimizing Large Language Model (LLM) and AI agent workloads in production environments. As organizations progressively incorporate intricate AI chains into their core applications, traditional Application Performance Monitoring (APM) tools often prove inadequate, lacking the necessary granular, semantic visibility to manage these non-deterministic systems effectively. Fallom bridges this critical gap by providing end-to-end tracing for every LLM call, capturing vital data points such as prompts, outputs, tool calls, token usage, latency, and cost per call. This comprehensive visibility empowers engineering, DevOps, and product teams to transform opaque AI operations into transparent, debuggable, and cost-controllable processes. Utilizing a single OpenTelemetry-native SDK, Fallom allows teams to instrument their applications swiftly, enabling real-time monitoring, expedited debugging of agentic workflows, and accurate attribution of AI spending across various models, teams, and customers. Additionally, Fallom ensures compliance with evolving regulations, such as the EU AI Act, by offering enterprise-grade audit trails essential for regulatory adherence.
About OpenMark AI
OpenMark AI is a web application for task-level LLM benchmarking. You describe what you want to test in plain language, run the same prompts against many models in one session, and compare cost per request, latency, scored quality, and stability across repeat runs, so you see variance, not a single lucky output.
The product is built for developers and product teams who need to choose or validate a model before shipping an AI feature. Hosted benchmarking uses credits, so you do not need to configure separate OpenAI, Anthropic, or Google API keys for every comparison.
You get side-by-side results with real API calls to models, not cached marketing numbers. Use it when you care about cost efficiency (quality relative to what you pay), not just the cheapest token price on a datasheet.
OpenMark AI supports a large catalog of models and focuses on pre-deployment decisions: which model fits this workflow, at what cost, and whether outputs are consistent when you run the same task again. Free and paid plans are available; details are shown in the in-app billing section.